PeterWem
Aktiv medlem
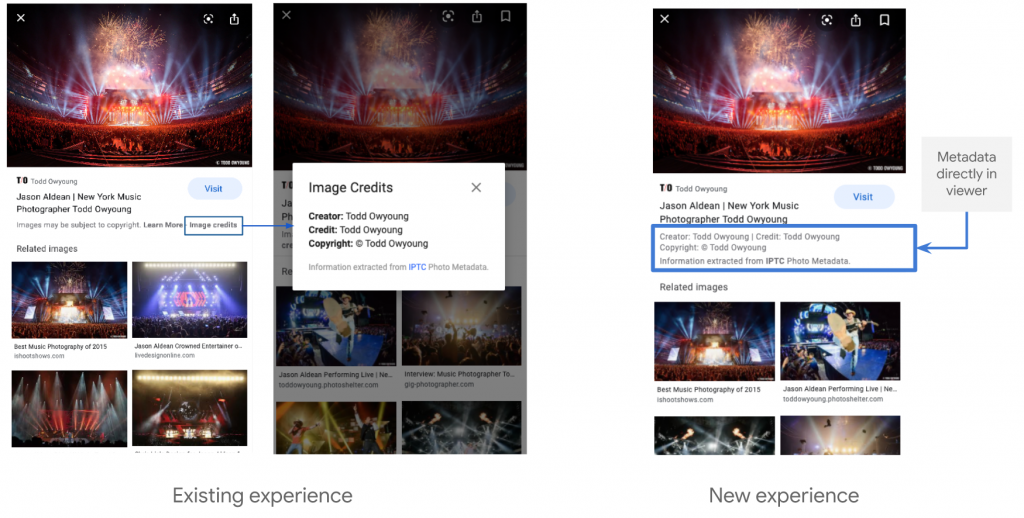
Google jobbar på (beta) att synliggöra vilken licens en bild har och vart man som bildsökare kan vända sig för att licensiera om så önskas. Redan nu visar Google vid bildsökning IPTC-fälten Creator, Credit och Copyright.
Vad som är på gång är alltså licensdelen, men i betastadie, där fälten Web Statement of Rights och Licensor URL kan användas. Web Statement of Rights ska vara en URL som pekar mot vilken licens en bild har medan Licensor URL kan vara en URL till vart man kan vända sig för att köpa en licens.
IPTC har en guide för vilka fält som ska användas och IPTC har en testbild där man kan jämföra dess metadata med sin egna bilds metadata.
Vilka fördelar finns med att fylla i dessa fält? Man kan åtminstone hoppas på att Google höjer upp ens bilder bland dess bildsök, men framför allt blir det tydligt vart en potentiell köpare kan vända sig när bilden inte ligger på ens egna hemsida.
Program för att ändra IPTC-fält? År 2020 är det kanske tvärtom lättare att skriva vilka fotoprogram som inte klarar det. Canon Digital Photo Professional 4 är ett som enbart kan läsa IPTC men inte ändra.
Vad som är på gång är alltså licensdelen, men i betastadie, där fälten Web Statement of Rights och Licensor URL kan användas. Web Statement of Rights ska vara en URL som pekar mot vilken licens en bild har medan Licensor URL kan vara en URL till vart man kan vända sig för att köpa en licens.
IPTC har en guide för vilka fält som ska användas och IPTC har en testbild där man kan jämföra dess metadata med sin egna bilds metadata.
Vilka fördelar finns med att fylla i dessa fält? Man kan åtminstone hoppas på att Google höjer upp ens bilder bland dess bildsök, men framför allt blir det tydligt vart en potentiell köpare kan vända sig när bilden inte ligger på ens egna hemsida.
Program för att ändra IPTC-fält? År 2020 är det kanske tvärtom lättare att skriva vilka fotoprogram som inte klarar det. Canon Digital Photo Professional 4 är ett som enbart kan läsa IPTC men inte ändra.
Bilagor
Senast ändrad: